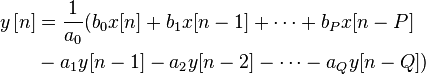{kind=link}
{kind=link}

As the name implies, content-addressable storage is a storage where an object placement is defined by its contents.
Hash table is an associative array which can map keys to values. It is different from binary search tree in the sense, that lookup and insertion time is constant. Let's see how it can be implemented. Let's imagine we need to use strings as keys and integer values as values. We can use hash function like CRC16, which converts any byte array into 16-bit value. The hash function can be applied to any string, so any string is mapped into 16-bit value. We then declare an array with size of 0x10000 integers for values. Value storing is simple:
storage[CRC16(key)]=value
Value lookup is also simple:
return storage[CRC16(key)]
The example is simplified for the sake of demonstration, and in fact, workable only in the ideal world, where hash functions are also ideal ( perfect hash function. In practice, several strings can produce the same CRC16 hash value, it's called "collision". In real world implementations of hash table, collisions are also inevitable, but they are handled in various ways. Simplest way is to connect linked list to each "bucket".
Anyway, hash table's main advantage is that it allows quick lookups and insertions. Indeed, you need just to calculate hash value of key and found corresponding element in array. So this time is constant (O(1)). Main disadvantage is that hash value calculation may be slow itself.
Intuitively, we can say that this is great at least for sets, but hash table is also used for associative arrays. "dict" and "set" in Python are implemented using hash table. C++11 standard has unordered_set, unordered_map, unordered_multiset and unordered_multimap which are implemented using hash table. Indeed: std::set and std::map in C++ are stored in always sorted form, because they are implemented using binary search trees. "unordered" in name means that hash table can't preserve any order of elements.
Which is better (or faster), binary search tree or hash map? Some experienced programmers just tries them all: binary search tree, hash map, linked list and the simple array, and then measure performance of each approach. These data structures may behave differently for various number of elements, various environment and cache memory setup. Linked list for small number of elements (~10) can outperform both binary search tree and hash map. Simple array for small number of elements can also outperform linked list (due to cache spatial locality, elements in linked list can be scattered across the memory and be accessed slower than as in sequential array).
Now let's say you work with strings a lot. You've got huge amount of long strings. One idea quickly came to mind: is it possible to deduplicate them somehow? Compress? To store each incarnation of string only once? This is called string interning. You basically store all your string in one single place, (associative) array. When you need to store another string, there is a function which is looking for duplicate in the array. If found, it returns pointer to it. If not, it adds it and returns pointer to the newly created string in array.
This leads to a significant advantage: no need to compare strings character-by-character, just compare their addresses! And if their addresses are in function arguments or CPU registers, string comparison procedure may not access memory at all.
This is a reason why immutable strings are so cool and used at least in Java, Python, Lua, etc. This is why you cannot modify mutable string in Python (because string array is "untouchable"), you can only create new one. This is, however, has a disadvantage: it's absurd to create new 100MB string if you need just change one byte in it. Well, this is why some programming languages also offers "mutable" versions of strings (at least Java and .NET languages). Python 3 has "bytearray" mutable data type.
See also: https://en.wikipedia.org/wiki/Immutable_object.
In OOP this is also called flyweight pattern. Boost has flyweight library.
So if you work with a lot of strings with a lot of duplicates among them, and you have no plans to modify them all, you may use immutable strings. If you plan to modify vast majority of your strings, or you work mostly with unique strings, you may consider mutable strings or byte buffers.
String interning implementation may use hash tables or not, but if it uses, each string will have its personal space somewhere in the memory.
Symbol in LISP has a name and also attached function or variable to it. LISPers use symbols heavily without anything attached to it, this is somewhat like enumerations/constants/macros in C. You may define 'red, 'green, 'blue symbols without any numerical value attached to them, and then compare these symbols with each other. Each symbol has unique address, like string in string interning.
It's LISP's way to implement symbol table.
Now that's the point where disctinction between LISP comparison operators lie.
EQ (EQ? in Scheme) compares just addresses of symbols or cells, it's fast, but doesn't consider cell's contents at all.
In Racket (Scheme dialect) manual we can find the same thing, paraphrased:
The eq? operator compares two values, returning #t when the values refer to the same object.
( http://docs.racket-lang.org/reference/eval-model.html?q=object )
EQL (EQV? in Scheme) compares cons cell's contents, but not addresses.
EQUAL (EQUAL? in Scheme) does "deep" comparison, i.e., compares all linked cons cells (or objects) recursively, hence, slow.
Now let's apply content-addressable storage to file sharing service, like Dropbox. It's not a secret that some part of all shared files are big media files (music, movies) and also big installation files of some popular software. At a file sharing service end we would like to compress (or deduplicate) all this information somehow. One of the simplest way to do it is to calculate hash (using SHA1 algorithm, for example) of each file uploaded to a service (or cloud) and inspect it, is this file is already stored somewhere on our servers? If yes, replace it with a link to it. If not, store it and provide link. And you'll never need to scan all the files to find duplicates.
Even more than that. SHA1 hash produces 160 bits or 20 bytes. Let's say, we have some huge file sharing service and we allocated 256 servers for it. The first byte of file hash can be a pointer to the server. Scalability is easy, you can just add more servers and modify the rules how hash is mapped to server ID.
I don't know how popular file sharing services are made internally (including Dropbox), but this is one of the simplest ways to implement it. There are even filesystems for this, like this one: https://en.wikipedia.org/wiki/Venti.
One disadvantage is that if you provide encryption at user end, all instances of some installation file (Firefox, for example) will be different for each user.
git uses content-addressable storage actively. It stores every file and every file state compressed and addresses content by its SHA1 hash. For example:
./objects/4a/cde9ab6dd9bf439ff2cbddb47d5e96b1f2e3ad ./objects/61/d7f2fcb4d4aa0c55abb07f0cca6fd6ffa91e00 ./objects/2e/c39aec17a9e53d21dcdafd8cdbe3ae7ada8c57 ./objects/8b/35c7d4622c1aa11531166e4bd7d1901c9d5d2b ...
Each this file under "objects" directory usually has some other file under revision control, and the file name is SHA1 hash of that file. This is efficient salvation from data duplication.
This has several benefits. The single file can be referenced from many file trees, but stored only once. File (or object) comparison is extremely fast: just compare its IDs.
More on git: //yurichev.com/blog/git.
It's possible to insert mathematical equations into Wikipedia articles in LaTeX format. Here is an example article with such: https://en.wikipedia.org/wiki/Infinite_impulse_response. Here we can see how these equations are added using the <math> tag: https://en.wikipedia.org/w/index.php?title=Infinite_impulse_response&action=edit§ion=2. Each is rendered into PNG picture which you see in your web browser. One of them is: https://upload.wikimedia.org/math/d/a/6/da6b5a9647adfd9f91d05db2f9ba9c1b.png.
Obviously, there are may be several Wikipedia articles with the same equation in it. Why to render them all if only unique ones must be rendered?
In readme file of Math Mediawiki extension (which do the job) we can find:
A rasterized PNG file will be written to the output directory, named for the MD5 hash code.
And here is fragment of its source code:
/**
* Tries to match the LaTeX Formula given as argument against the
* formula cache. If the picture has not been rendered before, it'll
* try to render the formula and drop it in the picture cache directory.
*
* @param string formula in LaTeX format
* @returns the webserver based URL to a picture which contains the
* requested LaTeX formula. If anything fails, the resultvalue is false.
*/
function getFormulaURL($latex_formula) {
// circumvent certain security functions of web-software which
// is pretty pointless right here
$latex_formula = preg_replace("/>/i", ">", $latex_formula);
$latex_formula = preg_replace("/_image_format;
...
( https://www.mediawiki.org/wiki/Manual:Running_MediaWiki_on_Windows/math.php )
Indeed, the filename of PNG file is MD5 hash of the equation.
And here is another website offering LaTeX rendering service: http://www.quicklatex.com/. Submit some LaTeX formatted data and get PNG file for blogging or posting into social network. I've submitted this:
\sum_{j=0}^Q a_{j} y[n-j] = \sum_{i=0}^P b_{i}x[n-i]
And I've got PNG file at the following URL: http://quicklatex.com/cache3/ef/ql_af3c42e5c853afd80a9c065e1d2cf7ef_l3.png. I also submitted the same equation to the website later, using my VPN and even Tor, the output PNG file had the same URL. Indeed, many website users may submit same LaTeX input, why to render it again each time? Supposedly, this website author(s) also does some hashing.
UPD: Discussion on HN: https://news.ycombinator.com/item?id=10391347.
... can use it all.
Also:
The identity of indiscernibles is an ontological principle that states that there cannot be separate objects or entities that have all their properties in common. That is, entities x and y are identical if every predicate possessed by x is also possessed by y and vice versa. It states that no two distinct things (such as snowflakes) can be exactly alike, but this is intended as a metaphysical principle rather than one of natural science. A related principle is the indiscernibility of identicals, discussed below. A form of the principle is attributed to the German philosopher Gottfried Wilhelm Leibniz. While some think that Leibniz's version of the principle is meant to be only the indiscernibility of identicals, others have interpreted it as the conjunction of the identity of indiscernibles and the indiscernibility of identicals (the converse principle). Because of its association with Leibniz, the indiscernibility of identicals is sometimes known as Leibniz's law. It is considered to be one of his great metaphysical principles, the other being the principle of noncontradiction and the principle of sufficient reason (famously been used in his disputes with Newton and Clarke in the Leibniz–Clarke correspondence).
( src )