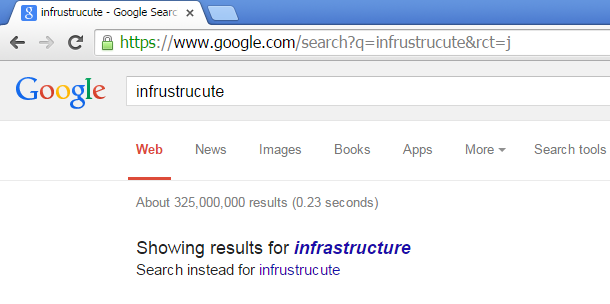
Almost all Internet users sometimes typing so fast and see something like this:
Google (and any other search engine) detect typos and misspellings with the help of information that input word ("infrustructure") is really rare (according to their database) and it can be transformed to a very popular word ("infrastructure", again, in their database) using just single editing operation.
This is called fuzzy string matching or approximate string matching.
One of the simplest and popular fuzzy string matching metrics is Levenshtein distance, it is just a number of editing operations (inserting, deleting, replacing) required to transform one string to another.
Let's test it in Wolfram Mathematica:
In[]:= DamerauLevenshteinDistance["wombat", "combat"] Out[]= 1
So it requires one editing operation to transform "wombat" into "combat" or back. Indeed, these words are different only in one (first) character.
Another example:
In[]:= DamerauLevenshteinDistance["man", "woman"] Out[]= 2
So it takes two editing operations to transform "man" to "woman" (two insertions). Or two deletions to transform "woman" to "man".
These words has only one character in common:
In[]:= DamerauLevenshteinDistance["water", "wine"] Out[]= 3
No wonder it requires 3 operations to transform one to another.
And now completely different words:
In[]:= DamerauLevenshteinDistance["beer", "wine"] Out[]= 4
4 editing operations for 4-character words meaning that each character in word must be replaced in order to transform.
There is a variant of grep which works approximately: agrep (wikipedia article, source code, more information). It is a standard package at least in Ubuntu Linux.
Let's pretend, I forgot how to spell name of Sherlock Holmes correctly. I've downloaded "The Adventures of Sherlock Holmes", by Arthur Conan Doyle from the Gutenberg library here.
Let's try agrep:
$ agrep -1 "Holms" pg1661.txt ... To Sherlock Holmes she is always THE woman. I have seldom heard ... I had seen little of Holmes lately. My marriage had drifted us ...
-1 mean that agrep would match words with Levenshtein distance of 1 editing operation. Indeed, "Holms" word is almost equal to "Holmes" with one character deleted.
The following command will not find any Holmes word ("Homs" is different from "Holmes" by 2 characters):
agrep -1 "Homs" pg1661.txt
But this will do:
agrep -2 "Homs" pg1661.txt
Fuzzy string matching algorithms are very popular nowadays at a websites, because it's almost impossible to demand correct spelling from its users.
Let's try to find typos in Wikipedia. It's size is tremendous, so I'll take only one part of june 2015 dump: enwiki-20150602-pages-meta-current9.xml-p000665001p000925001.bz2.
And here is my Python script. I use opensource Levenshtein distance Python module, which can be found here. It has very simple function named distance, which just takes two strings on input and returns Levenshtein distance.
What my script just takes all words from Wikipedia dump and build a dictionary, somewhat resembling to search index, but my dictionary reflects number of occurrences within Wikipedia dump (i.e., word popularity). Words in dictionary are limited by 6 characters, all shorter words are ignored. Then the script divides the whole dictionary by two parts. The first part is called "probably correct words" and contains words which are very popular, i.e., occurred most frequently (more than 200-300 times in the whole Wikipedia dump). The second part is called "words to check" and contain rare words, which occurred less than 10 times in the dump.
Then the script takes each "word to check" and calculates distance between it and an each word in the "probably correct words" dictionary. If the resulting distance is 1 or 2, it may be a typo and it's reported.
Here is example report (number in parenthesis is a number of occurrences of the "rare" word in the whole dump):
typo? motori (7) suggestions= [u'motors'] typo? critera (7) suggestions= [u'criteria'] typo? constitucional (7) suggestions= [u'constitutional'] typo? themselve (7) suggestions= [u'themselves'] typo? germano (7) suggestions= [u'german', u'germany', u'germans'] typo? synonim (7) suggestions= [u'synonym'] typo? choise (7) suggestions= [u'choose', u'choice']
These are clearly typos/misspellings. It seems, "choise" is a very popular typo: https://archive.is/CaMTD. (I made snapshot of Wikipedia search page because someone may correct these typos very soon).
Some reported words are not typos, for example:
typo? streel (2) suggestions= [u'street'] typo? arbour (2) suggestions= [u'harbour']
These are just rare words, and my script didn't collected big enough dictionary with these. Keep in mind, my script doesn't have its own English dictionary, its dictionary is built using Wikipedia itself.
The full list of typos my script found is: enwiki2015-current9-dist1.txt. Keep in mind, it's not whole Wikipedia, only it's part (since I do not own powerful computers and my script is very far from optimized).
Update: I added the list of all suspicious typos and misspellings for the whole Wikipedia: enwiki2015.typos.txt.
When the script reports words which matching words in dictionary by distance of 2, the report will be bigger.
For example:
typo? heigth (1) suggestions= [u'eighth', u'heights', u'health', u'height', u'length'] typo? contributuons (1) suggestions= [u'contribution', u'contributions', u'contributors'] typo? stapel (1) suggestions= [u'stayed', u'shaped', u'chapel', u'stated', u'states', u'staged', u'stages'] typo? seling (1) suggestions= [u'belong', u'spelling', u'sailing', u'feeling', u'setting', u'seeking', u'sending', u'spring', u'helping', u'serving', u'seeing', u'saying', u'telling', u'dealing', u'saving', u'string', u'selling', u'ruling'] typo? beading (1) suggestions= [u'meaning', u'bearing', u'heading', u'breeding', u'beating', u'hearing', u'wedding', u'beijing', u'sending', u'binding', u'needing', u'breaking', u'eating', u'pending', u'dealing', u'reading', u'wearing', u'trading', u'leading', u'leaving', u'ending', u'boarding', u'feeding'] typo? scying (1) suggestions= [u'acting', u'flying', u'buying', u'scoring', u'spring', u'seeing', u'saying', u'paying', u'saving', u'string', u'trying']
The full list is here: enwiki2015-current9-dist2.txt.
In this example, I use English language Wikipedia, byt my script can be easily extended to any other language. Just write your own str_is_latin() function.
Another extremely important application of fuzzy string matching is data entry applications where it's very easy to make mistakes in spelling of someone's names and surnames.
There is also application is spam filtering, because spammers try to write some well-known word(s) in many different ways to circumvent spam filters.
Peter Norvig explains how to write spelling corrector as the one used by Google: http://norvig.com/spell-correct.html.
You create a website for whatever you want and allow users to register and choice a password. You create some password guidelines: a password can't contain this, that, etc.
A popular requirement is something like:
"Passwords must not contain your username, or more than two consecutive characters from your full name (if your name is "John Smith" then your password cannot contain "joh" or "ith"; however it could contain "jo" or "th")."
One easy way to check this is just comparing username and password (as well as password hint) using Levenshtein distance...
One can find domain ideas using Levenshtein distance.
