
(The following text has been copypasted to the Mathematics for programmers.)
TL;DR: collect statistics, for a given natural language, what words come most often after a word/pair of words/triplet of words.
What are most chess moves played after 1.e4 e5 2.Nf3 Nf6? A big database of chess games can be queried, showing statistics:
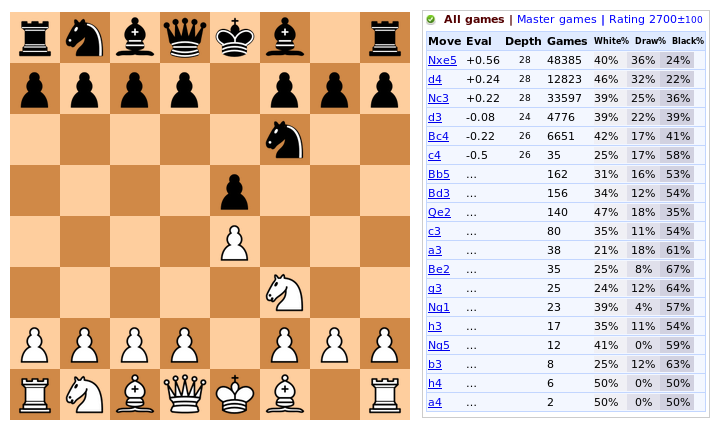
( from https://chess-db.com/ )
Statistics shown is just number of games, where a corresponding 3rd move was played.
The same database can be made for natural language words.
This is a well-known joke: https://en.wikipedia.org/wiki/Dissociated_press, https://en.wikipedia.org/wiki/SCIgen, https://en.wikipedia.org/wiki/Mark_V._Shaney.
I wrote a Python script, took Sherlock Holmes stories from Gutenberg library...
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# python 3! due to random.choices()
import operator, random
from collections import defaultdict
with open ("all.txt", "r") as myfile:
data=myfile.read()
sentences=data.lower().replace('\r',' ').replace('\n',' ').replace('?','.').replace('!','.').replace('“','.').replace('”','.').replace("\"",".").replace('‘',' ').replace('-',' ').replace('’',' ').replace('\'',' ').split(".")
def remove_empty_words(l):
return list(filter(lambda a: a != '', l))
# key=list of words, as a string, delimited by space
# (I would use list of strings here as key, but list in not hashable)
# val=dict, k: next word; v: occurrences
first={}
second={}
def update_occ(d, seq, w):
if seq not in d:
d[seq]=defaultdict(int)
d[seq][w]=d[seq][w]+1
for s in sentences:
words=s.replace(',',' ').split(" ")
words=remove_empty_words(words)
if len(words)==0:
continue
for i in range(len(words)):
if i>=1:
update_occ(first, words[i-1], words[i])
if i>=2:
update_occ(second, words[i-2]+" "+words[i-1], words[i])
"""
print ("first table:")
for k in first:
print (k)
# https://stackoverflow.com/questions/613183/how-do-i-sort-a-dictionary-by-value
s=sorted(first[k].items(), key=operator.itemgetter(1), reverse=True)
print (s[:20])
print ("")
"""
"""
print ("second table:")
for k in second:
print (k)
# https://stackoverflow.com/questions/613183/how-do-i-sort-a-dictionary-by-value
s=sorted(second[k].items(), key=operator.itemgetter(1), reverse=True)
print (s[:20])
print ("")
"""
text=["it", "is"]
# https://docs.python.org/3/library/random.html#random.choice
def gen_random_from_tbl(t):
return random.choices(list(t.keys()), weights=list(t.values()))[0]
text_len=len(text)
# generate at most 100 words:
for i in range(200):
last_idx=text_len-1
tmp=text[last_idx-1]+" "+text[last_idx]
if tmp in second:
new_word=gen_random_from_tbl(second[tmp])
else:
# fall-back to 1st order
tmp2=text[last_idx]
if tmp2 not in first:
# dead-end
break
new_word=gen_random_from_tbl(first[tmp2])
text.append(new_word)
text_len=text_len+1
print (" ".join(text))
And here are some 1st-order Markov chains. First part is a first word. Second is a list of words + probabilities of appearance of each one, in the Sherlock Holmes stories. However, probabilities are in form of words' numbers.
In other word, how often each word appears after a word?
return
[('to', 28), ('or', 12), ('of', 8), ('the', 8), ('for', 5), ('with', 4), ('by', 4), ('journey', 4), ('and', 3), ('when', 2), ('ticket', 2), ('from', 2), ('at', 2), ('you', 2), ('i', 2), ('since', 1), ('on', 1), ('caused', 1), ('but', 1), ('it', 1)]
of
[('the', 3206), ('a', 680), ('his', 584), ('this', 338), ('it', 304), ('my', 295), ('course', 225), ('them', 167), ('that', 138), ('your', 137), ('our', 135), ('us', 122), ('her', 116), ('him', 111), ('an', 105), ('any', 102), ('these', 92), ('which', 89), ('all', 82), ('those', 75)]
by
[('the', 532), ('a', 164), ('his', 67), ('my', 39), ('no', 34), ('this', 31), ('an', 30), ('which', 29), ('your', 21), ('that', 19), ('one', 17), ('all', 17), ('jove', 16), ('some', 16), ('sir', 13), ('its', 13), ('him', 13), ('their', 13), ('it', 11), ('her', 10)]
this
[('is', 177), ('agreement', 96), ('morning', 81), ('was', 61), ('work', 60), ('man', 56), ('case', 43), ('time', 39), ('matter', 37), ('ebook', 36), ('way', 36), ('fellow', 28), ('room', 27), ('letter', 24), ('one', 24), ('i', 23), ('young', 21), ('very', 20), ('project', 18), ('electronic', 18)]
no
[('doubt', 179), ('one', 134), ('sir', 61), ('more', 56), ('i', 55), ('no', 42), ('other', 36), ('means', 36), ('sign', 34), ('harm', 23), ('reason', 22), ('difficulty', 22), ('use', 21), ('idea', 20), ('longer', 20), ('signs', 18), ('good', 17), ('great', 16), ('trace', 15), ('man', 15)]
Now some snippets from 2nd-order Markov chains.
the return
[('of', 8), ('track', 1), ('to', 1)]
return of
[('sherlock', 6), ('lady', 1), ('the', 1)]
for the
[('use', 22), ('first', 12), ('purpose', 9), ('sake', 8), ('rest', 7), ('best', 7), ('crime', 6), ('evening', 6), ('ebooks', 6), ('limited', 6), ('moment', 6), ('day', 5), ('future', 5), ('last', 5), ('world', 5), ('time', 5), ('loss', 4), ('second', 4), ('night', 4), ('remainder', 4)]
use of
[('the', 15), ('anyone', 12), ('it', 6), ('project', 6), ('and', 6), ('having', 2), ('this', 1), ('my', 1), ('a', 1), ('horses', 1), ('some', 1), ('arguing', 1), ('troubling', 1), ('artificial', 1), ('invalids', 1), ('cocaine', 1), ('disguises', 1), ('an', 1), ('our', 1)]
you may
[('have', 17), ('copy', 13), ('be', 13), ('do', 9), ('choose', 7), ('use', 6), ('obtain', 6), ('convert', 6), ('charge', 6), ('demand', 6), ('remember', 5), ('find', 5), ('take', 4), ('think', 3), ('possibly', 3), ('well', 3), ('know', 3), ('not', 3), ('say', 3), ('imagine', 3)]
the three
[('of', 8), ('men', 4), ('students', 2), ('glasses', 2), ('which', 1), ('strips', 1), ('is', 1), ('he', 1), ('gentlemen', 1), ('enterprising', 1), ('massive', 1), ('quarter', 1), ('randalls', 1), ('fugitives', 1), ('animals', 1), ('shrieked', 1), ('other', 1), ('murderers', 1), ('fir', 1), ('at', 1)]
it was
[('a', 179), ('the', 78), ('not', 68), ('only', 40), ('in', 30), ('evident', 28), ('that', 28), ('all', 25), ('to', 21), ('an', 18), ('my', 17), ('at', 17), ('impossible', 17), ('indeed', 15), ('no', 15), ('quite', 15), ('he', 14), ('of', 14), ('one', 12), ('on', 12)]
Now two words is a key in dictionary. And we see here an answer for the question "how often each words appears after a sequence of two words?"
Now let's generate some rubbish:
it is just to the face of granite still cutting the lower part of the shame which i would draw up so as i can t have any visitors if he is passionately fond of a dull wrack was drifting slowly in our skin before long vanished in front of him of this arch rebel lines the path which i had never set foot in the same with the heads of these have been supplemented or more waiting to tell me all that my assistant hardly knowing whether i had 4 pounds a month however is foreign to the other hand were most admirable but because i know why he broke into a curve by the crew had thought it might have been on a different type they were about to set like a plucked chicken s making the case which may help to play it at the door and called for the convenience of a boat sir maybe i could not be made to draw some just inference that a woman exactly corresponding to the question was how a miners camp had been dashed savagely against the rock in front of the will was drawn across the golden rays and it it is the letter was composed of a tall stout official had come the other way that she had been made in this i expect that we had news that the office of the mud settling or the most minute exactness and astuteness represented as i come to see the advantages which london then and would i could not speak before the public domain ebooks in compliance with any particular paper edition as to those letters come so horribly to his feet upon the wet clayey soil but since your wife and of such damage or cannot be long before the rounds come again whenever she might be useful to him so now my fine fellow will trouble us again and again and making a little wizened man darted out of the baskervilles *** produced by roger squires updated editions will be the matter and let out forty three diamonds of the attack we carried him into the back and white feather were but a terrible fellow he is not for your share in an instant holmes clapped his hands and play with me anyhow i d ha known you under that name in a considerable treasure was hid for no other it is the unofficial force the shutter open but so far as to what i say to me like that which is rather too far from at ease for i knew that we were driving; but soon it came just as he opened it myself i was not a usual signal between you and you thought it might be removed to a magistrate than upon the luminous screen of the one word would he have wanted there are business relations between him and we listened to his eyes to the spot as soon as their master s affairs of life since she was but one day we hoped would screen me from under his arm chair of shining red leather chair his flask in his chair and gave me his name is sherlock holmes took each face of a barmaid in bristol and marry her but learned from dr it is selden the criminal or lunatic who had left a match might mar my career had reached the tower of the crime was committed before twelve foolish tradesmen in a bad lot though the authorities are excellent at amassing facts though what its object might be a better nerve for the creature flapped and struggled and writhed his hands in her bosom lady hilda was down on the table and the curious will so suddenly upon the floor were now nearly five thousand pounds will be impossible but i struck him down and roared into the shadow of the thing seemed simplicity itself said i you seem most fortunate in having every characteristic of the place is deserted up to keep some clandestine appointment and found as i have no desire to settle this little matter of fact of absolute ignorance and he with a similar pearl without any light upon what he had found ourselves at the time and my heart sank for barrymore at the close of november and holmes fears came to think over the afghan campaign yet shown by this time at which he now and i have seen his death this morning he walked straight into
By first look, these pieces of text are visually OK, but it is senseless. Some people (including me) find it amusing.
Spammers also use this technique to make email message visually similar to a meaningful text, albeit it is not meaningful at all, rather absurdic and funny.
It's surprising how easy this can be turned into something rather practically useful.
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import operator
from collections import defaultdict
with open ("all.txt", "r") as myfile:
data=myfile.read()
sentences=data.lower().replace('\r',' ').replace('\n',' ').replace('?','.').replace('!','.').replace('“','.').replace('”','.').replace("\"",".").replace('‘',' ').replace('-',' ').replace('’',' ').replace('\'',' ').split(".")
def remove_empty_words(l):
return list(filter(lambda a: a != '', l))
# key=list of words, as a string, delimited by space
# (I would use list of strings here as key, but list in not hashable)
# val=dict, k: next word; v: occurrences
first={}
second={}
third={}
def update_occ(d, seq, w):
if seq not in d:
d[seq]=defaultdict(int)
d[seq][w]=d[seq][w]+1
for s in sentences:
words=s.replace(',',' ').split(" ")
words=remove_empty_words(words)
if len(words)==0:
continue
for i in range(len(words)):
# only two words available:
if i>=1:
update_occ(first, words[i-1], words[i])
# three words available:
if i>=2:
update_occ(second, words[i-2]+" "+words[i-1], words[i])
# four words available:
if i>=3:
update_occ(third, words[i-3]+" "+words[i-2]+" "+words[i-1], words[i])
"""
print ("third table:")
for k in third:
print (k)
# https://stackoverflow.com/questions/613183/how-do-i-sort-a-dictionary-by-value
s=sorted(third[k].items(), key=operator.itemgetter(1), reverse=True)
print (s[:20])
print ("")
"""
test="i can tell"
#test="who did this"
#test="she was a"
#test="he was a"
#test="i did not"
#test="all that she"
#test="have not been"
#test="who wanted to"
#test="he wanted to"
#test="wanted to do"
#test="it is just"
#test="you will find"
#test="you shall"
#test="proved to be"
test_words=test.split(" ")
test_len=len(test_words)
last_idx=test_len-1
def print_stat(t):
total=float(sum(t.values()))
# https://stackoverflow.com/questions/613183/how-do-i-sort-a-dictionary-by-value
s=sorted(t.items(), key=operator.itemgetter(1), reverse=True)
# take 5 from each sorted table
for pair in s[:5]:
print ("%s %d%%" % (pair[0], (float(pair[1])/total)*100))
if test_len>=3:
tmp=test_words[last_idx-2]+" "+test_words[last_idx-1]+" "+test_words[last_idx]
if tmp in third:
print ("* third order. for sequence:",tmp)
print_stat(third[tmp])
if test_len>=2:
tmp=test_words[last_idx-1]+" "+test_words[last_idx]
if tmp in second:
print ("* second order. for sequence:", tmp)
print_stat(second[tmp])
if test_len>=1:
tmp=test_words[last_idx]
if tmp in first:
print ("* first order. for word:", tmp)
print_stat(first[tmp])
print ("")
First, let's also make 3rd-order Markov chains tables. There are some snippets from it:
the return of
[('sherlock', 6), ('lady', 1), ('the', 1)]
the use of
[('the', 13), ('anyone', 12), ('project', 6), ('having', 2), ('a', 1), ('horses', 1), ('some', 1), ('troubling', 1), ('artificial', 1), ('invalids', 1), ('disguises', 1), ('it', 1)]
of the second
[('stain', 5), ('floor', 3), ('page', 1), ('there', 1), ('person', 1), ('party', 1), ('day', 1)]
it was in
[('the', 9), ('vain', 5), ('a', 4), ('his', 2), ('83', 1), ('one', 1), ('motion', 1), ('truth', 1), ('my', 1), ('this', 1), ('march', 1), ('january', 1), ('june', 1), ('me', 1)]
was in the
[('room', 3), ('habit', 3), ('house', 2), ('last', 2), ('loft', 2), ('spring', 1), ('train', 1), ('bar', 1), ('power', 1), ('immediate', 1), ('year', 1), ('midst', 1), ('forenoon', 1), ('centre', 1), ('papers', 1), ('best', 1), ('darkest', 1), ('prime', 1), ('hospital', 1), ('nursery', 1)]
murder of the
[('honourable', 1), ('discoverer', 1)]
particulars of the
[('crime', 1), ('inquest', 1), ('habits', 1), ('voyage', 1)]
the death of
[('the', 8), ('sir', 8), ('captain', 3), ('their', 2), ('this', 2), ('his', 2), ('her', 2), ('dr', 2), ('sherlock', 1), ('mrs', 1), ('a', 1), ('van', 1), ('that', 1), ('drebber', 1), ('mr', 1), ('stangerson', 1), ('two', 1), ('selden', 1), ('one', 1), ('wallenstein', 1)]
one of the
[('most', 23), ('best', 3), ('main', 3), ('oldest', 2), ('greatest', 2), ('numerous', 2), ('corners', 2), ('largest', 2), ('papers', 2), ('richest', 2), ('servants', 2), ('moor', 2), ('finest', 2), ('upper', 2), ('very', 2), ('broad', 2), ('side', 2), ('highest', 2), ('australian', 1), ('great', 1)]
so far as
[('i', 17), ('to', 8), ('that', 2), ('the', 2), ('it', 2), ('was', 1), ('we', 1), ('they', 1), ('he', 1), ('you', 1), ('a', 1), ('your', 1), ('this', 1), ('his', 1), ('she', 1)]
You see, they looks as more precise, but tables are just smaller. You can't use them to generate rubbish. 1st-order tables big, but "less precise".
And here I test some 3-words queries, like as if they inputted by user:
"i can tell" * third order. for sequence: i can tell you 66% my 16% them 16% * second order. for sequence: can tell you 23% us 17% me 11% your 11% this 5% * first order. for word: tell you 35% me 25% us 6% him 5% the 4% "she was a" * third order. for sequence: she was a blonde 12% child 6% passenger 6% free 6% very 6% * second order. for sequence: was a very 4% man 3% small 3% long 2% little 2% * first order. for word: a very 2% man 2% little 2% few 2% small 1% "he was a" * third order. for sequence: he was a man 11% very 7% young 3% tall 3% middle 2% * second order. for sequence: was a very 4% man 3% small 3% long 2% little 2% * first order. for word: a very 2% man 2% little 2% few 2% small 1% "i did not" * third order. for sequence: i did not know 22% say 9% even 3% tell 3% mind 3% * second order. for sequence: did not know 11% take 3% wish 3% go 2% say 2% * first order. for word: not a 4% be 4% have 3% been 3% to 2% "all that she" * third order. for sequence: all that she said 100% * second order. for sequence: that she had 22% was 19% would 7% is 5% has 5% * first order. for word: she was 12% had 10% is 5% said 3% would 3% "have not been" * third order. for sequence: have not been able 25% here 25% employed 12% shadowed 12% personally 12% * second order. for sequence: not been for 9% in 6% there 6% a 4% slept 4% * first order. for word: been a 5% in 4% the 2% so 2% taken 1% "who wanted to" * third order. for sequence: who wanted to see 100% * second order. for sequence: wanted to see 15% know 15% speak 10% ask 10% hide 5% * first order. for word: to the 11% be 6% me 4% his 2% my 2% "he wanted to" * third order. for sequence: he wanted to know 50% do 50% * second order. for sequence: wanted to see 15% know 15% speak 10% ask 10% hide 5% * first order. for word: to the 11% be 6% me 4% his 2% my 2% "wanted to do" * third order. for sequence: wanted to do the 100% * second order. for sequence: to do with 23% so 14% it 10% the 4% and 3% * first order. for word: do you 24% not 20% with 6% so 4% it 4% "it is just" * third order. for sequence: it is just possible 42% as 33% killing 4% such 4% in 4% * second order. for sequence: is just possible 25% as 22% the 8% a 8% to 5% * first order. for word: just as 13% now 5% a 4% to 3% the 2% "you will find" * third order. for sequence: you will find that 20% it 20% me 8% the 8% a 6% * second order. for sequence: will find it 19% that 17% the 9% me 7% a 5% * first order. for word: find that 13% the 10% it 9% out 8% a 6% "you shall" * second order. for sequence: you shall have 15% see 12% know 12% hear 9% not 9% * first order. for word: shall be 20% have 7% not 4% see 3% i 3% "proved to be" * third order. for sequence: proved to be a 42% the 14% too 4% something 4% of 4% * second order. for sequence: to be a 11% the 3% in 3% able 2% so 2% * first order. for word: be a 7% the 4% in 2% of 2% no 2%
Perhaps, results from all 3 tables can be combined, with the data from 3rd order table used in highest priority (or weight).
And this is it - this can be shown to user. Aside of Conan Doyle works, your software can collect user's input to adapt itself for user's lexicon, slang, memes, etc. Of course, user's "tables" should be used with highest priority.
I have no idea, what Apple/Android devices using for hints generation, when user input text, but this is what I would use as a first idea.
As a bonus, this can be used for language learners, to get the idea, how a word is used in a sentence.
... is used. This is a very useful function: weights (or probabilities) can be added.
For example:
#!/usr/bin/env python3
import random
for i in range(1000):
print (random.choices("123", [25, 60, 15]))
Let's generate 1000 random numbers in 1..3 range:
$ python3 tst.py | sort | uniq -c
234 ['1']
613 ['2']
153 ['3']
"1" is generated in 25% of cases, "2" in 60% and "3" in 15%. Well, almost.
Comma can be a separator as well, etc...
... including Conan Doyle's stories (2.5M). https://yurichev.com/blog/markov/files. Surely, any other texts can be used, in any language...
Another related post is about typos: https://yurichev.com/blog/fuzzy_string/.
→ [list of blog posts] Please drop me email about bug(s) and/or suggestion(s): my emails.