{kind=link}

Во время эксперимента по обучению программированию, накопились задачи, которые я использовал. Решать можно на любых ЯП, конечно.
Как вычислить x в степени 5? ($x^5$) Решение в лоб: x*x*x*x*x. Здесь 4 операции умножения. А можно ли обойтись мЕньшим кол-вом операций умножения?
Подсказка из известной книги:
"Отгадай-ка вот это: Человеку нужно порубить восемь корд дров..."
Я говорю: "Он начинает рубить корды через одну на три части", - потому что уже слышал эту загадку."
( src )
Оригинал на английском:
... A man has eight cords of wood to chop..."
And I said, "He starts by chopping every other one in three parts," because I had heard that one.
Есть у вас только функции min(x,y) и max(x,y). Используя их, как отсортировать список из трех значений? Из четырех?
Для сортировки 3-х значений, достаточно только 3 вызова ф-ции min(x,y) и 3 вызова max(x,y). Для сортировки 4-х значений, достаточно 5 вызовов первой и 5 - второй.
Дешевые китайские цифровые термометры, когда температура немного меняется на границе двух целых значений, начинают дребезжать между ними. Как от этого избавиться? Решение простое, реализуется на любом дешевом микроконтроллере.
В клонах игры Lines, когда пользователь жмет мышей на квадрат, куда двигать шарик, обыкновенно происходит поиск кратчайшего пути. Как это сделать? Можно также в лабиринте вроде такого.
Я забыл пароль от RAR-архива.
Я помню, что там было имя кого-то из моей (гипотетической) семьи: jake, melissa, oliver, emily. Я помню, что там был год рождения кого-то из моей (гипотетической) семьи: 1987, 1954, 1963. Я помню что там был какой-то из этих символов (ведь это так рекомендуется всеми): ["!","@","#","$","%","&","*","-","=","_","+",".",","]
Но я не помню порядок следования этих элементов.
Нужно составить список всех возможных паролей, на основании этой инфы. Их ~936.
(Конечно, вы не сможете так взломать соц.сеть в инете, но скормить эти пароли ломалке RAR-архивов - легко.)
Полезно начать с наивного решения, а потом подумать, как всё это дело можно улучшить.
Можно немного сложнее - каждый латинский символ в разных case (маленькая/большая) и некоторые символы могут быть в виде leetspeak-а (o->0, e->3, i->1), но тут уже итак всё ясно, как это сделать.
Как сделать свой base64, где вы можете использовать не 64 символа, а произвольное кол-во, скажем, 71. И так, чтобы КПД кодировщика было максимальное, т.е., использование всех 71 символов было равномерным.
Одной инструкцией процессора менять значение в регистре между 1234 и 4567. Пользоваться дополнительной памятью нельзя. (Изначально в регистре 1234.)
Backtracking: рассовать файлы разного размера по флешкам разного размера, да так, чтобы использовать минимум флешек.
В былые времена -- рассовать сборник песен по аудиокассетам, чтобы поменьше пустых мест оставалось в конце. Вариант -- записывать свои сборники музыки на CD-R-ах. Они поначалу дорогие были, так что не хотелось использовать их неэффективно.
Более трудный вариант -- есть набор виртуальных машин, у каждой свои требования по памяти и пространству на винтах. Есть набор серверов, куда их нужно рассовать. А так как датацентр у нас старый и давно не обновлялся, то сервера попадаются с очень разными сочетаниями объема памяти и винтов.
Есть какие-то датчики, они выдают результат, но не в целых числах, а в вещественных. Вам для чего-то нужно обрабатывать результаты. Складывать, делить, итд. Может быть, масштабировать, нормализовать. В общем, вам нужны минимум 4 операции над вещественными числами: + - * / А контроллер дешевый (как и большинство оных), без FPU. Как работать с вещественными числами? Большая точность не нужна. Штуки 3 цифры до запятой и после: xxx.xxx
Сделать это легко. Всё это часто описывается в embedded-книгах и сайтах. Но интереснее самому переизобрести велосипед.
И снова микроконтроллеры. Задача скорее на эрудицию, но всё равно интересно поразмыслить. Как известно, простейший генератор случайных чисел выглядит так:
seed=seed*const1 + const2 % 2^32 (ну или 2^16)
Предположим, у вас очень дешевый микроконтроллер, там нет операции умножения. Вернее, вы можете её реализовать (через пачку операций сложения), но это громоздко и медленно.
Возможно сделать достойный ГПСЧ без операции умножения и даже сложения. И даже без дополнительной таблицы-массива. Используя только несколько базовых логических операций. Этот алгоритм невероятно известный и полезный, много где используется и в электронике -- в спутниках связи, в мобилах, в военке даже (раньше -- точно).
Если вам нужно протестировать свой ГПСЧ, то самый простой тест такой -- если он 16-битный, то он должен худо-бедно выдать каждое 16-битное значение примерно по одному разу... Также, утилита ent в UNIX-ах...
Свой калькулятор в духе того что описывается в книгах Страуструпа про С++.
Затем микро-Эксель, как тут. Как разбираться с циркулярными зависимостями? Пользователю надо отдать ошибку вроде "ячейки X и Y зависят друг от друга", но продолжить считать таблицу без этих ячеек.
Сокращение выражений вроде "x + x" -> "2 * x"; "x + y + 3 + x - 1" -> "2*x + y + 2"; "x + y - x" -> "y".
В общем, то, как это делает Wolfram Alpha. Достаточно учитывать только 4 операции, может быть, еще возведение в степень.
Вы вводите текст в Android/iOS, внизу выскакивают подсказки. Как их генерировать? Как оказалось, это примитивный алгоритм. Задача на сообразительность даже. Алгоритм размером не более чем на один экран, не пользуясь сторонними библиотеками. Возможно, именно такой и юзают в Android-е, во всяком случае, мне эта идея пришла в голову, когда я наблюдал за подсказками. В начале, впрочем, его нужно натренировать при помощи большого кол-ва текстов (худлит, например), на этом языке (английский, русский). Но это не "нейронки", не байесовый фильтр, итд, это всё намного проще.
Игральная кость имеет 6 граней. Как сделать ГПСЧ генерирующий значение в пределах 0..5? Если просто "rand() % 6" страдает от modulo bias - некоторые значения выпадают чаще других, это проблема многих видоигр. Проверить ваш ГПСЧ легко -- генерируете $10^6$ значений, каждое значение 0..5 должно выпасть примерно столько же раз, сколько и остальные.
В git: берем большой файл, commit-им, потом посреди оного вставляем 1-2 байта. git это понимает и в дельте будет совсем немного. Интересно подумать о том, как он это делает. И кстати, довольно быстро.
Иными словами, задача может быть diff для бинарных файлов, если второй файл почти такой же, только в середину что-то всунули.
Алгоритм простой, но не сильно известный, наверное потому что потребность в таком не очень большая, т.к., ПО редко когда вот так работает со своими бинарными файлами.
Те, у кого дети, знают, как мучительно придумать имя. Имена все или слишком заезженные, или слишком экзотические. Трудновато бывает найти разумную середину. Предположим, мы создаем мегапопсовый телесериал для показа в прайм-тайм. И сценаристы столкнулись с такой же проблемой. Как присвоить имена-фамилии персонажам, чтобы звучали естественно? И не ударяться в крайности вроде Иван/Петр и Аристарх/Евлампий? Как написать прогу, способную выдать штук 20 случайных имен+фамилий?
Будем пользоваться статистикой. Здесь статистика по именам-фамилиям, правда, по США: 1 2 Если кто найдет по RU или UA, пользуйтесь ею...
При генерации, пусть имена повторяются, но примерно с той же вероятностью, с какой это случается в реальной жизни, например, 2-3 Димы в одном школьном классе или ВУЗовской группе...
Подсказка. Для упрощения, представьте, что мы живем в таком социуме, где всего 5 имен, с такой частотой:
Какой получится прога?
Я видел это в известной софтине. Есть сервер и клиент. Клиенту нужно логиниться в сервер при помощи логина и пароля.
Сервер не хранит пароль в открытом виде. Потому что если кто-то украдет базу сервера, то при помощи пароля юзера, быть может, получится залогиниться еще куда-то. Из-за этого, все подряд форумы в интернете хранят пароль в хешированном виде. Используя sha1, md5 (если не успели проапдейтить), итд.
В нашем случае, сервер также хранит хешированный пароль. Однако, если злоумышленник может подслушивать весь траффик между вами и сервером, он может подслушать и пароль и даже хешированный пароль, а затем используя это залогиниться в сервер.
Как сделать так, чтобы злоумышленник не смог этого сделать? В наше время используют SSL/TLS. Но есть способы куда проще. У вас в наличии ф-ции хеширования вроде sha1, ф-ции симметричного шифрования вроде DES, AES и стандартная библиотека Си.
Также нужна защита от MITM-атаки -- нужно учесть, что злоумышленник может на лету менять сетевые пакеты, и от сервера к клиенту и назад.
Важный момент -- клиент не должен передавать пароль, он должен только доказать, что знает его, а это немного другое.
Во многих учебниках по электронике, когда читаете про закон Кирхгофа, попадаются такие иллюстрации:
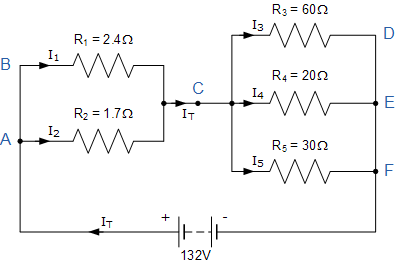
Известно, как подсчитать суммарное сопротивление этой пачки резисторов. Но в реальном мире, резисторы маркируются не точным сопротивлением. Есть какие-то допуски: 5%, 10% или даже больше. В каких пределах будет суммарное сопротивление, если у указанных резисторов допуск -- 10%?
Наивный алгоритм поиска подстроки в строке требует len(input)*len(substring) шагов. Более быстрые алгоритмы давно известны, но придумать такой сходу -- трудно.
Но можно немного упростить задачу. Создать алгоритм для поиска фиксированной подстроки: "TEST". Тестовая строка: "THIS IS A TEXT TEST" Придумайте алгоритм, который найдет в этой строке подстроку "TEST" (немного) быстрее, чем наивный способ.
Если вам интересно, правильно ли вы решили, можете написать мне емыло, я могу подтвердить (или нет).
Yes, I know about these lousy Disqus ads. Please use adblocker. I would consider to subscribe to 'pro' version of Disqus if the signal/noise ratio in comments would be good enough.