{kind=link}

My library is huge and I'm a bookworm. For years, I've been using a local search engine: DocFetcher and dtSearch for Windows and Recoll for Linux.
A local search engine may be more suitable than Google because you can narrow down your search to your own carefully collected books/papers/texts, while Google would offer you everything it has.
For years, I was happy with DocFetcher and Recoll, but I wanted something even simpler, since I'm a strong adherent of suckless philosophy (my other suckless-style solution is a primitive clipboard manager).
So I wrote a Bash script that just prepares text versions of PDFs (using pdftotext) and DJVUs/EPUBs/MOBIs (using calibre converter): src.
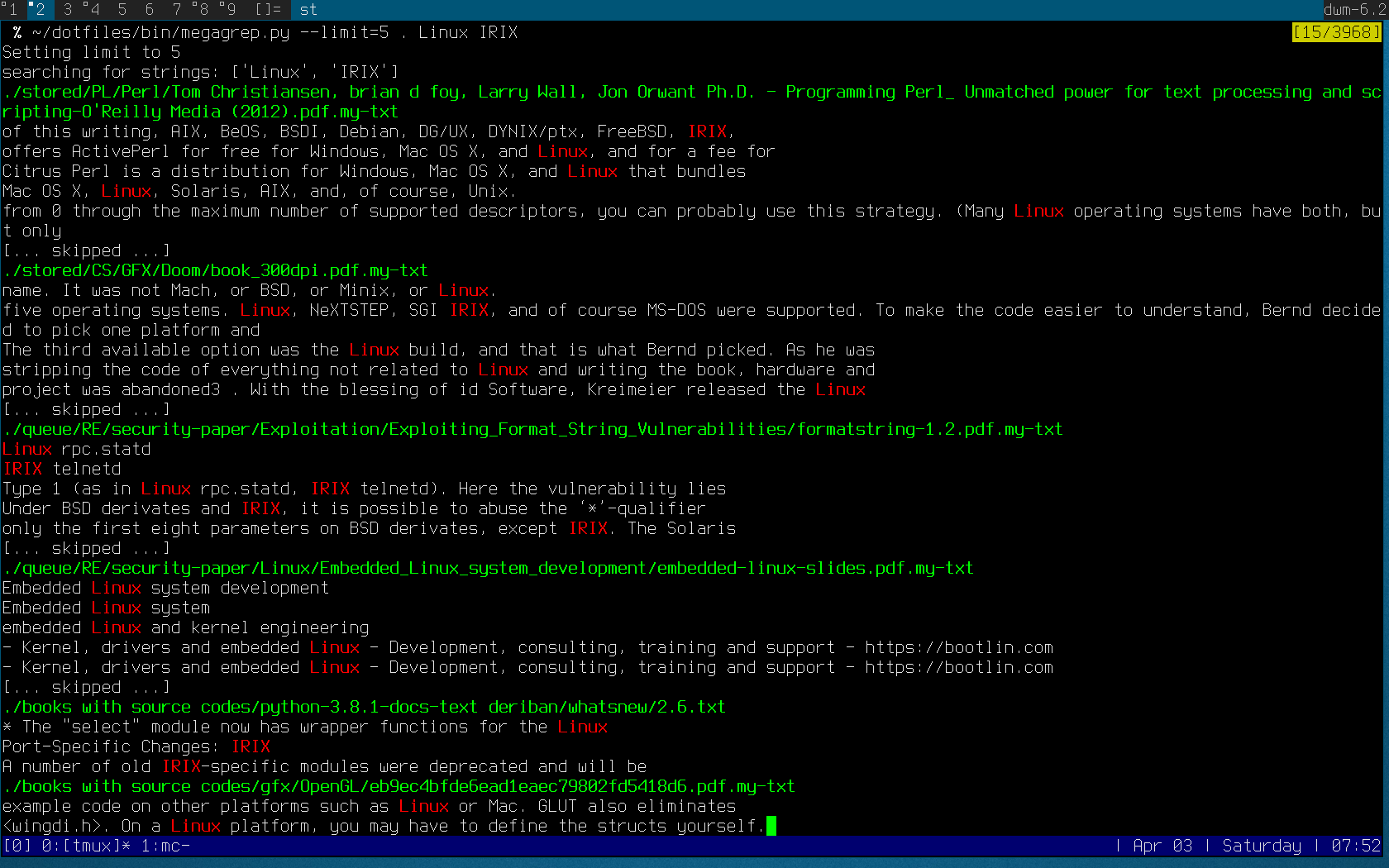
I have a *.my-txt file for almost any PDF/DJVU/EPUB/MOBI. All they are grep-able. Which book has a "SGI IRIX" substring?
% find . -name '*.my-txt' -type f -exec grep -l 'SGI IRIX' {} \;
./stored/CS/GFX/Doom/book_300dpi.pdf.my-txt
./queue/RE/security-paper/Linux/Embedded_Linux_system_development/embedded-linux-slides.pdf.my-txt
./unsorted/dictionaries/Benjamin W. Wah - Wiley Encyclopedia of Computer Science and Engineering, 5-Volume Set-Wiley-Interscience (2009).pdf.my-txt
./unsorted/networks/PPP Design, Implementation, and Debugging 2nd ed - J. Carlson (2000) WW.pdf.my-txt
./unsorted/unsorted/Unix/Linux/EN - Understanding the Linux kernel 2.pdf.my-txt
./unsorted sci magazines/LNAI 1104.pdf.my-txt
./unsorted sci magazines/LNAI 1104.djvu.my-txt
./current was in tablet/{BM} emacs/emacs.epub.my-txt
You can write a shell script to search several substring in the same text file. But I have my own version of grep that does this: searching for texts with two substrings ('Linux' and 'SGI'). But often, I just use midnight commander to search what I want.
Yes, grepping is slower than indexing. But no additional software is required. Reindexing is also simpler.
And of course, I want to find books where some term occurred, say, more than 10 times. I wrote the grep_count.sh script:
#!/usr/bin/env bash
count=$(cat "$1" | grep -c -i "$2")
if [ $count -gt 10 ];
then
echo $1, $count
fi
And that is how I use it:
% find . -name '*.my-txt' -type f -exec ./grep_count.sh {} "automated reasoning" \;
./stored/CS/Armin Biere - Handbook of Satisfiability/book.pdf.my-txt, 36
./stored/model checking/Handbook of Model Checking/Edmund M. Clarke, Thomas A. Henzinger, Helmut Veith, Roderick Bloem (eds.) - Handbook of Model Checking (2018).pdf.my-txt, 15
./queue/new bookz (Ontology etc)/(International Handbooks on Information Systems) Nicola Guarino, Daniel Oberle, Steffen Staab (auth.), Steffen Staab, Rudi Studer (eds.) - Handbook on Ontologies-Springer-Verlag Berlin Heidelberg (200.pdf.my-txt, 17
./queue/{2} Handbook of Practical Logic and Automated Reasoning (2009)/John Harrison-Handbook of Practical Logic and Automated Reasoning (2009).pdf.my-txt, 46
...
Yes, I know about these lousy Disqus ads. Please use adblocker. I would consider to subscribe to 'pro' version of Disqus if the signal/noise ratio in comments would be good enough.