(The following text has been copypasted to the SAT/SMT by example book.)
This is the most practically useful example in this series of blog posts. It can be used to parse config files in form option=number, but whitespaces are also handled -- around input string and around the 'equal' sign.
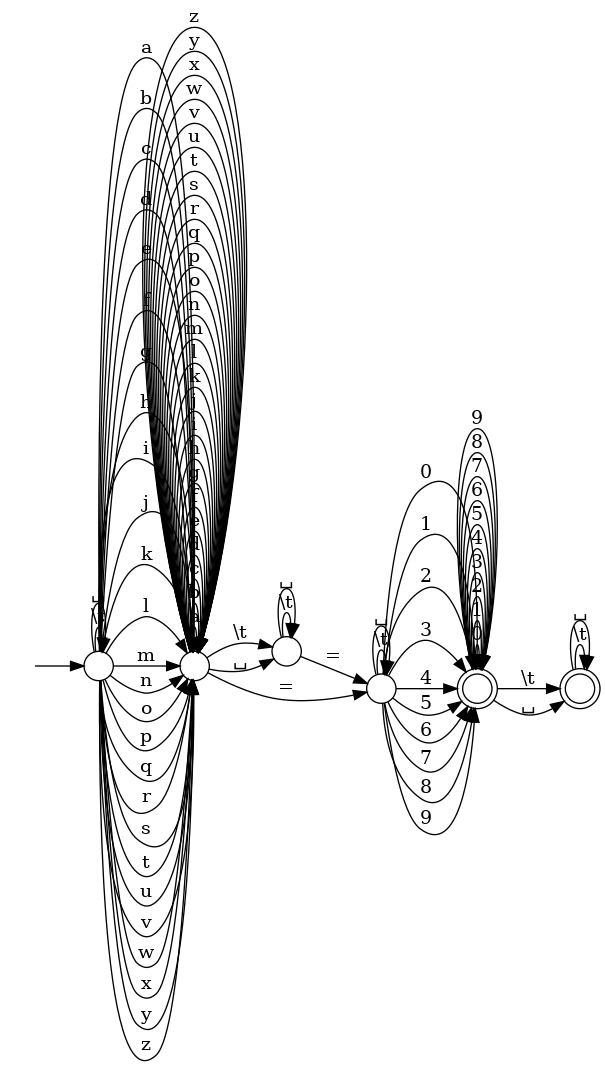
According to my utility, these are (random) sample input strings that can be accepted by the RE:
string matched: [zzzzzzzzzwt=09] string matched: [zzzzzzzzztkj=3] string matched: [zzzzzzzzzuj=5 ] string matched: [zzzzzzzzzy=16 ] string matched: [zzzzzzzzzzcr=9] string matched: [zzzzzzzzzzxz=2] string matched: [zzzzzzzzzuca=2] string matched: [zzzzzzzzzyd=44] string matched: [zzzzzzzzzuwj=5] string matched: [zzzzzzzzzvfj=3] string matched: [zzzzzzzzzs =13] string matched: [zzzzzzzzzt = 8] string matched: [zzzzzzzzzuu =5] string matched: [zzzzzzzzzwhi=1]
The DFA is complicated by first sight, but it's not:
Now the fun begins. Can we implement our own parser of such config files without the aid of RE? It turns out, a great programming exercise.
The first version. Using CBMC I 'compare' my version with the pure C DFA simulator produced by libfsm. (I did that already with other algorithms: 1, 2.)
#include <stdio.h>
#include "config.c"
// cbmc --trace --function check 1.c --unwind 11 --unwinding-assertions -DCBMC -DLEN=4
int naive(char* s)
{
// skip spaces
while (*s==' ')
s++;
char *tmp=s;
// read option (a-z)
for (;;)
{
if ((*s>='a') && (*s<='z'))
{
s++;
continue;
}
else
break;
};
// skip spaces
while (*s==' ')
s++;
// match '='
if (*s!='=')
return -1;
s++;
// skip spaces
while (*s==' ')
s++;
tmp=s;
// read option (0-9)
for (;;)
{
if ((*s>='0') && (*s<='9'))
{
s++;
continue;
}
else
break;
};
// skip spaces
while (*s==' ')
s++;
// all done!
return 1;
};
#ifdef CBMC
void check()
{
char s[LEN+1];
s[LEN]=0;
__CPROVER_assert (naive(s)==fsm_main(s), "assert");
};
#endif
int main()
{
//#define S " = "
#define S "b="
printf ("%d\n", naive(S));
printf ("%d\n", fsm_main(S));
};
int
fsm_main(const char *s)
{
const char *p;
enum {
S0, S1, S2, S3, S4, S5
} state;
state = S0;
for (p = s; *p != '\0'; p++) {
switch (state) {
case S0: /* start */
switch ((unsigned char) *p) {
case '\t':
case ' ': break;
case 'a':
case 'b':
case 'c':
case 'd':
case 'e':
case 'f':
case 'g':
case 'h':
case 'i':
case 'j':
case 'k':
case 'l':
case 'm':
case 'n':
case 'o':
case 'p':
case 'q':
case 'r':
case 's':
case 't':
case 'u':
case 'v':
case 'w':
case 'x':
case 'y':
case 'z': state = S1; break;
default: return -1; /* leaf */
}
break;
case S1: /* e.g. "a" */
switch ((unsigned char) *p) {
case 'a':
case 'b':
case 'c':
case 'd':
case 'e':
case 'f':
case 'g':
case 'h':
case 'i':
case 'j':
case 'k':
case 'l':
case 'm':
case 'n':
case 'o':
case 'p':
case 'q':
case 'r':
case 's':
case 't':
case 'u':
case 'v':
case 'w':
case 'x':
case 'y':
case 'z': break;
case '=': state = S2; break;
case '\t':
case ' ': state = S3; break;
default: return -1; /* leaf */
}
break;
case S2: /* e.g. "a=" */
switch ((unsigned char) *p) {
case '\t':
case ' ': break;
case '0':
case '1':
case '2':
case '3':
case '4':
case '5':
case '6':
case '7':
case '8':
case '9': state = S4; break;
default: return -1; /* leaf */
}
break;
case S3: /* e.g. "a\\x09" */
switch ((unsigned char) *p) {
case '=': state = S2; break;
case '\t':
case ' ': break;
default: return -1; /* leaf */
}
break;
case S4: /* e.g. "a=0" */
switch ((unsigned char) *p) {
case '0':
case '1':
case '2':
case '3':
case '4':
case '5':
case '6':
case '7':
case '8':
case '9': break;
case '\t':
case ' ': state = S5; break;
default: return -1; /* leaf */
}
break;
case S5: /* e.g. "a=0" */
switch ((unsigned char) *p) {
case '\t':
case ' ': break;
default: return -1; /* leaf */
}
break;
default:
; /* unreached */
}
}
/* end states */
switch (state) {
case S4: return 0x1; /* "[ \t]*[a-z]+[ \t]*=[ \t]*[0-9]+[ \t]*" */
case S5: return 0x1; /* "[ \t]*[a-z]+[ \t]*=[ \t]*[0-9]+[ \t]*" */
default: return -1; /* unexpected EOT */
}
}
What can go wrong? Running CBMC:
Trace for check.assertion.1:
State 17 file 1.c line 63 function check thread 0
----------------------------------------------------
s={ ' ', ' ', 'y', '=', 0 } ({ 00100000, 00100000, 01111001, 00111101, 00000000 })
Ouch, my naive parser can't parse the string " y=" correctly. It has no second part (a number) after the 'equality' sign. Probably I can fix it like that:
else
break;
};
+ // option must be non-empty
+ if (tmp==s)
+ return -1;
// skip spaces
while (*s==' ')
@@ -48,6 +51,9 @@
else
break;
};
+ // option must be non-empty
+ if (tmp==s)
+ return -1;
// skip spaces
while (*s==' ')
But it also has problems:
Trace for check.assertion.1:
State 17 file 2.c line 69 function check thread 0
----------------------------------------------------
s={ '\t', 'p', '=', '0', 0 } ({ 00001001, 01110000, 00111101, 00110000, 00000000 })
Ouch, I forgot about tabs! By code doesn't handle it.
int naive(char* s)
{
// skip spaces
- while (*s==' ')
+ while ((*s==' ') || (*s=='\t'))
s++;
char *tmp=s;
@@ -27,7 +27,7 @@
return -1;
// skip spaces
- while (*s==' ')
+ while ((*s==' ') || (*s=='\t'))
s++;
// match '='
@@ -36,7 +36,7 @@
s++;
// skip spaces
- while (*s==' ')
+ while ((*s==' ') || (*s=='\t'))
s++;
tmp=s;
@@ -56,7 +56,7 @@
return -1;
// skip spaces
- while (*s==' ')
+ while ((*s==' ') || (*s=='\t'))
s++;
Still problems:
Trace for check.assertion.1:
State 17 file 3.c line 69 function check thread 0
----------------------------------------------------
s={ 'j', '=', '9', -72, 0 } ({ 01101010, 00111101, 00111001, 10111000, 00000000 })
-72 is 0xffffffffffffffb8 or 0xb8, it is non-printable character, anyway. Fixing it:
if (tmp==s)
return -1;
- // skip spaces
- while ((*s==' ') || (*s=='\t'))
+ // at this point, only spaces and whitespaces are allowed
+ while (*s)
+ {
+ if ((*s!=' ') && (*s!='\t'))
+ {
+ return -1;
+ };
s++;
+ };
// all done!
return 1;
All cool, up to strings of length 15. It should be noted: 'unwind' parameter must be bigger by at least 1. But not too big, otherwise it will verify your code too slow.
% cbmc --trace --function check 4.c --unwind 16 --unwinding-assertions -DCBMC -DLEN=15 ... Solving with MiniSAT 2.2.1 with simplifier 55862 variables, 238864 clauses SAT checker: instance is UNSATISFIABLE Runtime decision procedure: 4.23306s ** Results: [check.assertion.1] assert: SUCCESS [naive.unwind.0] unwinding assertion loop 0: SUCCESS [naive.unwind.1] unwinding assertion loop 1: SUCCESS [naive.unwind.2] unwinding assertion loop 2: SUCCESS [naive.unwind.3] unwinding assertion loop 3: SUCCESS [naive.unwind.4] unwinding assertion loop 4: SUCCESS [naive.unwind.5] unwinding assertion loop 5: SUCCESS [fsm_main.unwind.0] unwinding assertion loop 0: SUCCESS ** 0 of 8 failed (1 iteration) VERIFICATION SUCCESSFUL
The final source code:
#include <stdio.h>
#include "config.c"
// cbmc --trace --function check 4.c --unwind 16 --unwinding-assertions -DCBMC -DLEN=15
int naive(char* s)
{
// skip spaces
while ((*s==' ') || (*s=='\t'))
s++;
char *tmp=s;
// read option (a-z)
for (;;)
{
if ((*s>='a') && (*s<='z'))
{
s++;
continue;
}
else
break;
};
// option must be non-empty
if (tmp==s)
return -1;
// skip spaces
while ((*s==' ') || (*s=='\t'))
s++;
// match '='
if (*s!='=')
return -1;
s++;
// skip spaces
while ((*s==' ') || (*s=='\t'))
s++;
tmp=s;
// read option (0-9)
for (;;)
{
if ((*s>='0') && (*s<='9'))
{
s++;
continue;
}
else
break;
};
// option must be non-empty
if (tmp==s)
return -1;
// at this point, only spaces and whitespaces are allowed
while (*s)
{
if ((*s!=' ') && (*s!='\t'))
{
return -1;
};
s++;
};
// all done!
return 1;
};
#ifdef CBMC
void check()
{
char s[LEN+1];
s[LEN]=0;
__CPROVER_assert (naive(s)==fsm_main(s), "assert");
};
#endif
int main()
{
//#define S " = "
#define S "b="
printf ("%d\n", naive(S));
printf ("%d\n", fsm_main(S));
};
Obviously, without tools like CBMC, you have a lots of unchecked vulnerable code.
Even harder RE: for CSV files. For the sake of simplicity, it only accepts strings consisting of 'a' or 'z'.
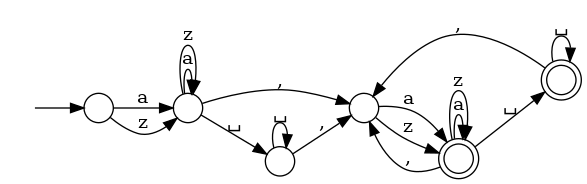
It's like 'nested' or 'recursive' RE. But probably too complicated -- more advanced parsed should be used for CSV instead of RE.
All the rest is syntactic sugar: "X+" is for "XX*", "X{3}" is for "XXX", "X{1-2}" is for "X|XX".
S. sugar is important in practice, but it's better to focus on fundamentals when you start learning.
All this code is like "grep", it doesn't return groups of parsed line, like MM, DD and YYYY separately. You can try hacking what libfsm produces in pure C to add this feature.
Further reading: blog posts about RE by Russ Cox is what I found interesting.

Yes, I know about these lousy Disqus ads. Please use adblocker. I would consider to subscribe to 'pro' version of Disqus if the signal/noise ratio in comments would be good enough.