Two more uses of information entropy metric
Downloading torrent files
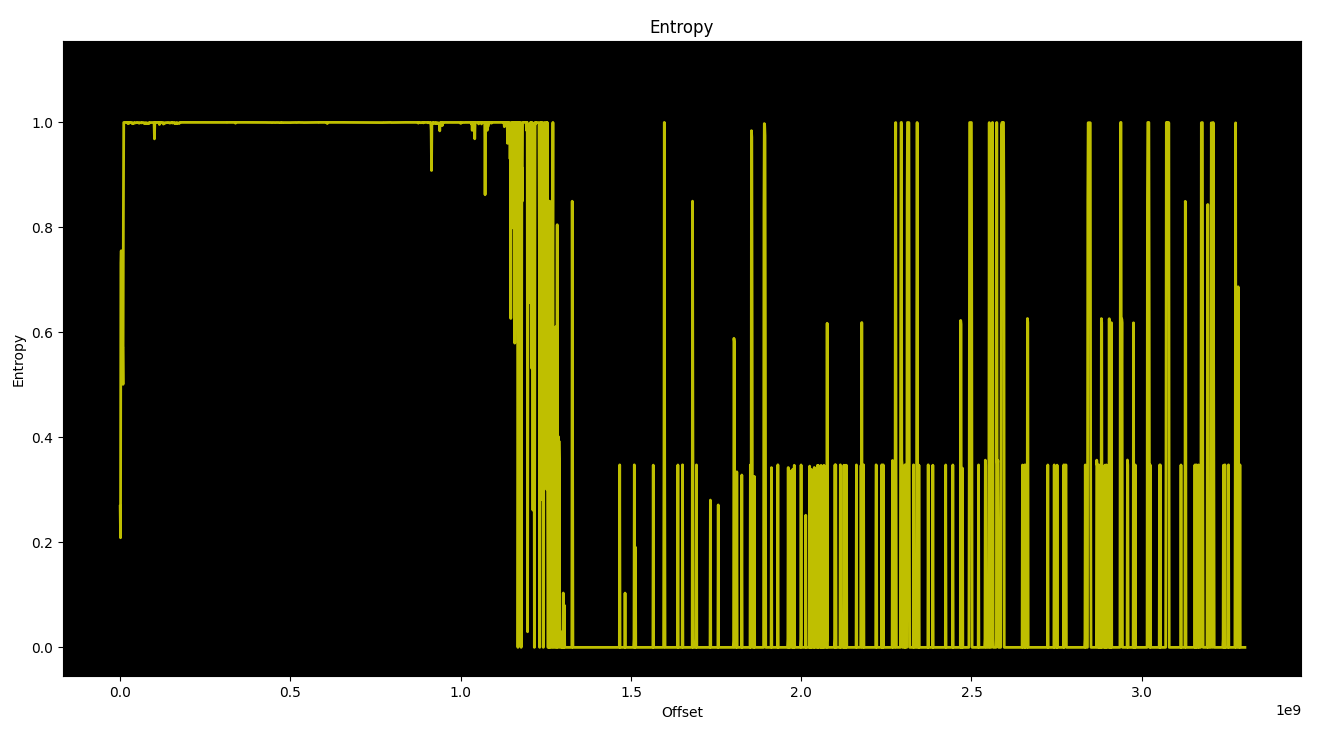
Using 'binwalk -E' or 'binwalk -E -F', you can easily see which blocks
of a torrent file are already downloaded, and which are zero/empty blocks...
As of high-entropy music and video files, you can quickly see if it was downloaded fully, without zero blocks remained.
A real example:
binwalk output
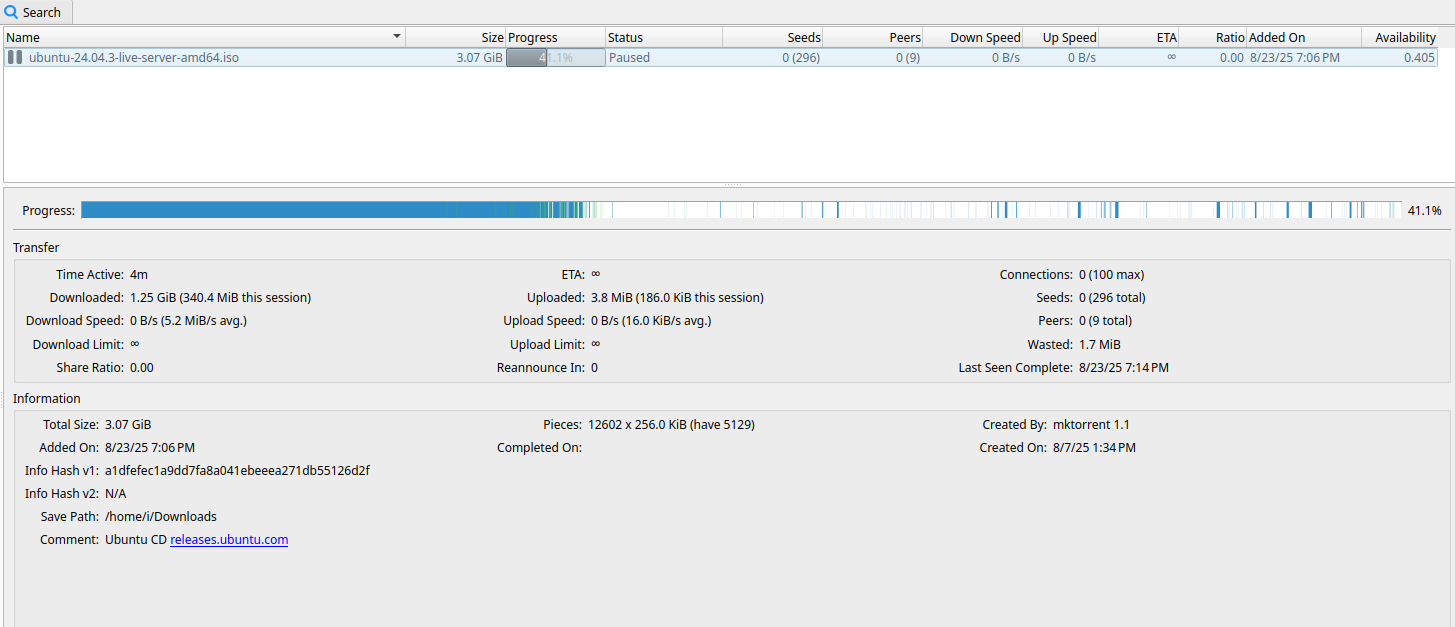
and
what qBittorrent shows.
I really do this when I find some (maybe (un)-finished) video file in Downloads directory.
Also, an archiver (like 7z, RAR, ZIP) can skip high-entropy files
(because they are already uncompressable)
to increase archiving speed.
(Entropy can be measured quickly by small random spots in file.)
A more sophisticated compressor (like gzip, bzip, xz)
can detect high-entropy spots in a file and skip them.
(the post first published at 20251110.)

If you noticed a typo/bug/error or have any suggestions, do not hesitate to drop me a note:
my emails.
Or use my zulip for feedback.
Thanks in advance!
Also, among my services is writing examples-rich manuals, references and help files.
If you like my work and want something similar for your (commercial) product:
contact me.
If you enjoy my work, you can support it on patreon.
Some time ago (before 24-Mar-2025) there was Disqus JS script for comments.
I dropped it --- it was so motley, distracting, animated, with too much ads.
I never liked it.
Also, comments din't appeared correctly (Disqus was buggy).
Also, my blog is too chamberlike --- not many people write comments here.
So I decided to switch to the model I once had at least in 2020 --- send me your comments
by email (don't forget to include URL to this blog post) and I will copy&paste it here manually.
Let's party like it's ~1993-1996,
in this ultimate, radical and uncompromisingly primitive pre-web1.0-style blog and website.
This website is best viewed under lynx/links/elinks/w3m.
{kind=link}
{kind=link}